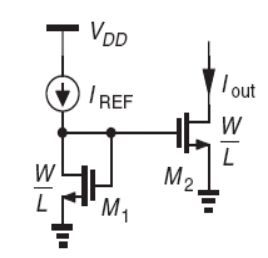
P(Θ=p)P(\Theta=p)P(Θ=p) 를 Beta(α,β)=pα−1(1−p)β−1∫01qα−1(1−q)β−1dq=pα−1(1−p)β−1B(α,β)Beta(\alpha, \beta) = \frac{p^{\alpha-1}(1-p)^{\beta-1}}{\int^1_0q^{\alpha-1}(1-q)^{\beta-1}dq} = \frac{p^{\alpha-1}(1-p)^{\beta-1}}{B(\alpha,\beta)}Beta(α,β)=∫01qα−1(1−q)β−1dqpα−1(1−p)β−1=B(α,β)pα−1(1−p)β−1 로 가정
사전 확률이 정규 분포 형태로 나타나기 위해 α=β=2\alpha=\beta=2α=β=2로 선정, P(Θ=p)=Beta(2,2)=p(1−p)B(2,2)P(\Theta=p) = Beta(2,2) = \frac{p(1-p)}{B(2,2)}P(Θ=p)=Beta(2,2)=B(2,2)p(1−p)
P(Θ=p∣N=n,K=k)P(\Theta=p|N=n, K=k)P(Θ=p∣N=n,K=k) 식을 정리하면 (nk)pk(1−p)n−kBeta(2,2)∫01(nk)qk(1−q)n−kBeta(2,2)dq=pk+1(1−p)n−k+1∫01qk+1(1−q)n−k+1dq\frac{\binom{n}{k}p^{k}(1-p)^{n-k}Beta(2,2)}{\int^1_0\binom{n}{k}q^{k}(1-q)^{n-k}Beta(2,2)dq} = \frac{p^{k+1}(1-p)^{n-k+1}}{\int^1_0q^{k+1}(1-q)^{n-k+1}dq}∫01(kn)qk(1−q)n−kBeta(2,2)dq(kn)pk(1−p)n−kBeta(2,2)=∫01qk+1(1−q)n−k+1dqpk+1(1−p)n−k+1 즉 베타분포 B(k+2,n−k+2)B(k+2, n-k+2)B(k+2,n−k+2)의 식으로 나타남
이 식의 최빈값은 mode=a−1a+b−2=k+1n+2mode = \frac{a-1}{a+b-2}=\frac{k+1}{n+2}mode=a+b−2a−1=n+2k+1로 나타난다.
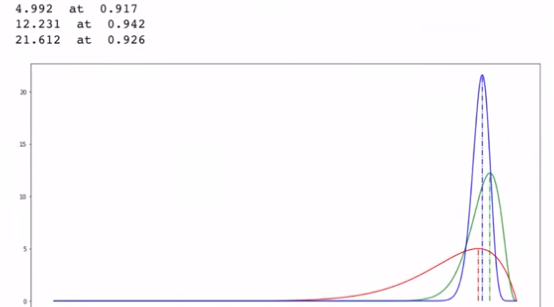
아래 두 선은 n=1, 2인 경우, 노란 선은 n=1000인 경우, 시행회수가 증가함에 따라 분포의 평균이 더 높은 확률로 표시되는 것을 볼 수 있다.
이를 통한 3가지 경우를 가정
(n,k)
(10,10)
(50,48)
(200,186)
B(k+2,n−k+2)B(k+2, n-k+2)B(k+2,n−k+2)
B(12,2)
B(62,4)
B(202,16)
적색 : (10,10) / 녹색 : (50, 48) / 청색 : (200, 186)
즉 50명 중 48명이 좋아요를 누른 경우가 좋아요를 누를 확률이 대략 94.2%가 됨을 알 수 있다.
배워야지 하다가 손 놓고 있던 파이썬을 뜻밖에 전공 과제로 인해 강제로 손에 잡게 되었다. 코딩하는게 참 머리를 많이 쓰게 한다 싶으면서도, 파이썬의 라이브러리를 이용한 간편성(numpy, matplotlib ...)과, 에디터의 다양성(주피터가 그렇게 편한 에디터인줄 몰랐다)에 파이썬의 매력이 상당하다 싶었던 참이었다.
그러던 차에 지난달 알쏭달쏭 C언어 책 리뷰에 이어 4월 미션 도서에 파이썬 도서인데다가, 마침 배워둬서 나쁘지 않겠다 싶을 딥러닝 관련 책이 있어 이 도서를 신청하게 되었다.
주제가 주제인 만큼 책의 두께는 꽤 되는 편이지만, 실제 카테고리를 보니 가볍게 머신러닝 이론부터 시작해서, 파이썬 기초부터 수학/그래프 라이브러리, 그리고 딥러닝으로 이루어지는 구조였다. 딱 한권 떼면 뭔가 한학기 전공과목을 배운 것 같다 싶은, 그런 구성이다.
괜찮은 내용 배치와 심심하지 않은 삽화 덕에 읽을 만은 한 편이다. 중간 중간 퀴즈가 있어 생각할 거리도 주는데, 공부에 도움이 된다기보다는 배운 내용을 두번 읽는 정도로 가볍게 훑는 느낌의 퀴즈이다.
아쉬운 점이 있었다면 1판이라 오타가 잡히지 않은 것인지, 아니면 출간 후 라이브러리에 변동이 있었는지는 모르겠지만 책 중간에 코드에 오류가 발생한 경우가 있었다.
from sklearn import cross_validation ... scores = cross_validation.cross_val_score(clf, X, y, cv=5)
라는 코드가 있는데, 이대로는 작동을 하지 않았고
from sklearn.model_selection import cross_val_score ... scores = cross_val_score(clf, X, y, cv=5)
의 양식으로 작성해야 코드가 동작했다.
책 내용의 구성은 파이썬으로 배우는 '딥러닝' 교과서 라기 보다는, '파이썬으로 배우는' 딥러닝 교과서에 가까운 느낌이다. 책 내용의 거의 딥러닝에 필요한 모듈인 파이썬-numpy(수학)-pandas(데이터)-matplotlib(시각화)-딥러닝으로 이어지는 구성인 만큼, 파이썬 지식이 충분하다면 이 책을 사도 그다지 읽을 부분이 많지는 않으리라 생각된다.
하지만 그 과정의 내용 자체가 상당히 성실하게 구성된 만큼 초심자에겐 확실한 가이드가, 중급자에겐 무난한 참고서 역할을 해 줄 수 있으리라 생각된다.
thermal R-G에 의해 정공의 시간에 따른 변화 ∂p∂t∣i−thermal−R−G=∂p∂t∣R−∂p∂t∣G=−cpNT(p−p0)=−cpNTΔp\\\frac{\partial p}{\partial t}|_{i-thermal-R-G}=\frac{\partial p}{\partial t}|_R-\frac{\partial p}{\partial t}|_G=-c_pN_T(p-p_0)\\=-c_pN_T\Delta p∂t∂p∣i−thermal−R−G=∂t∂p∣R−∂t∂p∣G=−cpNT(p−p0)=−cpNTΔp
p-type 반도체에서 thermal R-G에 의한 전자의 시간에 따른 변화∂n∂t∣i−thermal−R−G=−cnNTΔn\\\frac{\partial n}{\partial t}|_{i-thermal-R-G}=-c_nN_T\Delta n∂t∂n∣i−thermal−R−G=−cnNTΔn