728x90
Disk Structure
- Magnetic Disk : HDD 등
- Transfer Rate : 저장 장치 - 커뮤퍼 사이의 데이터 전송 속도
- Positioning Time(random-access time) : 디스크 암이 목표 실린더에 도달하는 시간(seek time)과 목표 섹터에 도달하는 시간(rotational latency)
- head crush : 디스크 암과 디스크가 맞닿는 현상
- Access Latency = Average access time = 평균 탐색 시간 + 평균 지연
- Average I/O time = average access time + (transfer amount / transfer rate) + controller overhead
- Logical block
- 디스크는 1차원의 logical block의 배열로 관리
- 논리적 주소가 물리적 주소를 의미하지는 않음
- garbage collector : 쓰레기 값이 저장된 block을 초기홫
Disk Scheduling
- seek time의 최소화
- request queue에 실린더 위치가 순서대로 입장
- ex) 98, 183, 37, 122, 14, 124, 65, 67
- head 위치는 53이라고 가정
- FCFS : 큐에 들어오는 순서대로 접근
- SSTF : 현 위치에서 seek time이 가장 짧은 위치로 먼저 접근
- SJF와 유사 : starvation 문제가 생길 수 있음
- SCAN : 디스크 암이 logical array의 양 끝 번갈아 왕복하며 처리
- elevator algorithm이라고도 부름
- 디스크 암과 실린더 위치에 따라 장시간 대기해야 하는 경우가 생길 수 있음
- C-SCAN
- 실린더의 처음부터 끝까지 순서대로 처리
- 실린더 끝까지 탐색하면 다시 처음으로 이동한 뒤 끝까지 이동하면서 처리
- 실린더 양 끝을 왕복하는 SCAN의 단점이 어느정도 해결
- C-LOOK
- Look : 큐의 최대/최소점에 도달하면 실린더는 반대 방향으로 탐색
- C-Look : Look으로 동작하되, C-SCAN과 같이 큐 최대점 도달 시 다시 최소점으로 이동한 후 처리
Disk Management
- Low-Level Formatting
- 물리적 포맷이라고도 함
- 디스크를 R/W 동작이 가능한 섹터로 분할
- 각 섹터는 정보, 데이터, ECC(Error Correction Code)가 저장
- 파티션 : 디스크를 논리적 단위로 분할
- 논리적 포맷 혹은 "파일 시스템을 만든다" 라고도 함
- 효율성을 위해 파일은 클러스터 단위로 처리 (디스크 > 블록, 파일 > 클러스터)
- 부팅 과정
- 롬에 저장된 BootStrap이 부팅 시 호출됨
- 디스크 0번 섹터(MBR)의 프로그램이 부트스트랩을 호출하는 기능을 함(Bootstrap Loader)
- Swap Space management
- page 파일을 만들어 관리하거나, swap 파티션을 할당하여 관리
- swap map : 커널은 swpap 사용 방식을 추적
- swap 공간이 없다 = 메모리 가용량이 없음 >> process kill or crash
RAID
- 저가의 디스크를 다수 연결하여 고성능 구현 (scale - out)
- mean time to failure : 고장 확률이 높아짐
- mean time to repair : 추가적인 고장 확률이 높음
- 다수의 디스크를 병렬로 기록 시 : 읽는 속도가 증가
- ex. 디스크의 mean time to failure = 100000, mean time to repair = 10
- mean time to data loss = 100000^2 / ( 2 * 10 ) = 500 * 10 ^ 6 (약 57000년)
- 실제로는 저장장치가 완전히 독립적이지 않으므로 이보다는 짧아짐
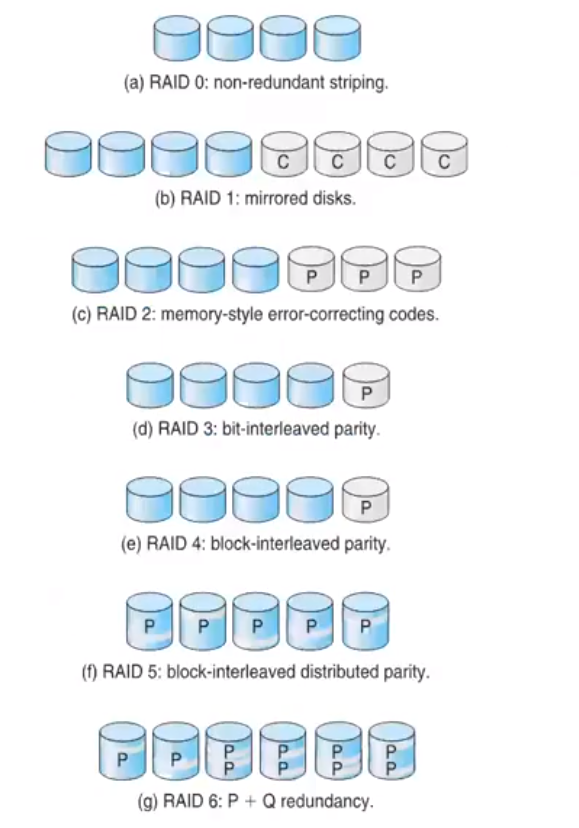
- Disk striping : 여러 개의 저장 장치를 하나의 단위로 취급
- RAID를 통해 성능을 높이거나, 저장장치의 신뢰성을 높일 수 있음
- RAID 0
- 큰 데이터를 각 저장장치로 분산
- 디스크 중 하나가 고장나면 전체 데이터가 손실
- RAID 1
- Mirroring 혹은 Shadowing으로 호칭
- 각 디스크의 복사본을 저장
- 한 쪽이 고장나도 안전한 대체 가능
- RAID 2 : ECC code를 사용
- RAID 3 : Bit Interleaved Pairty
- RAID 4 : Block Interleaved Parity / Parity disk가 고장 시 전체 데이터 손실
- RAID 5 : RAID 4에서 parity를 각 디스크로 분산
- RAID 6 : Parity 정보를 이중으로 기록
- RAID 1 + 0 / RAID 0 + 1

- 전자는 Striped Mirror, 후자는 Mirrored stripe
- 신뢰성과 성능 모두를 추구
- 디스크 구조상 RAID 1 + 0이 더 안전
- hot-spare : 비상용 디스크 / RAID 중 디스크 고장 시 빠른 대체
Stable Storage Implementation
- 데이터를 저장할 때 안전하게 보관하는 상태
- 1개 이상의 비휘발성 저장소에 복원 가능하도록 데이터를 저장
- Disk Write의 결과
- 정상 작동
- 부분 실패
- 완전 실패
728x90























