P(Θ=p)P(\Theta=p)P(Θ=p) 를 Beta(α,β)=pα−1(1−p)β−1∫01qα−1(1−q)β−1dq=pα−1(1−p)β−1B(α,β)Beta(\alpha, \beta) = \frac{p^{\alpha-1}(1-p)^{\beta-1}}{\int^1_0q^{\alpha-1}(1-q)^{\beta-1}dq} = \frac{p^{\alpha-1}(1-p)^{\beta-1}}{B(\alpha,\beta)}Beta(α,β)=∫01qα−1(1−q)β−1dqpα−1(1−p)β−1=B(α,β)pα−1(1−p)β−1 로 가정
사전 확률이 정규 분포 형태로 나타나기 위해 α=β=2\alpha=\beta=2α=β=2로 선정, P(Θ=p)=Beta(2,2)=p(1−p)B(2,2)P(\Theta=p) = Beta(2,2) = \frac{p(1-p)}{B(2,2)}P(Θ=p)=Beta(2,2)=B(2,2)p(1−p)
P(Θ=p∣N=n,K=k)P(\Theta=p|N=n, K=k)P(Θ=p∣N=n,K=k) 식을 정리하면 (nk)pk(1−p)n−kBeta(2,2)∫01(nk)qk(1−q)n−kBeta(2,2)dq=pk+1(1−p)n−k+1∫01qk+1(1−q)n−k+1dq\frac{\binom{n}{k}p^{k}(1-p)^{n-k}Beta(2,2)}{\int^1_0\binom{n}{k}q^{k}(1-q)^{n-k}Beta(2,2)dq} = \frac{p^{k+1}(1-p)^{n-k+1}}{\int^1_0q^{k+1}(1-q)^{n-k+1}dq}∫01(kn)qk(1−q)n−kBeta(2,2)dq(kn)pk(1−p)n−kBeta(2,2)=∫01qk+1(1−q)n−k+1dqpk+1(1−p)n−k+1 즉 베타분포 B(k+2,n−k+2)B(k+2, n-k+2)B(k+2,n−k+2)의 식으로 나타남
이 식의 최빈값은 mode=a−1a+b−2=k+1n+2mode = \frac{a-1}{a+b-2}=\frac{k+1}{n+2}mode=a+b−2a−1=n+2k+1로 나타난다.
아래 두 선은 n=1, 2인 경우, 노란 선은 n=1000인 경우, 시행회수가 증가함에 따라 분포의 평균이 더 높은 확률로 표시되는 것을 볼 수 있다.
이를 통한 3가지 경우를 가정
(n,k)
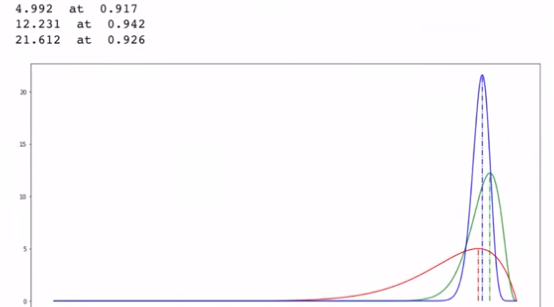
(10,10)
(50,48)
(200,186)
B(k+2,n−k+2)B(k+2, n-k+2)B(k+2,n−k+2)
B(12,2)
B(62,4)
B(202,16)
적색 : (10,10) / 녹색 : (50, 48) / 청색 : (200, 186)
즉 50명 중 48명이 좋아요를 누른 경우가 좋아요를 누를 확률이 대략 94.2%가 됨을 알 수 있다.