728x90
CPU scheduler
- ready queue 내의 프로세스를 선택하는 방식
- CPU 스케줄링 이 동작하게 되는 프로세스의 경우의 수
- running > waiting
- running > ready
- waiting > ready
- 프로세스 제거
- 1, 4의 경우 non-preemptive / 2, 3은 preemptive scheduling
- Dispatcher
- 기존 프로세스의 상태를 PCB에 저장/불러오기
- dispatch latency - dispatcher가 프로세스를 중단하고 다른 프로세스를 실행하기까지의 시간
Scheduling criteria
- 스케줄러의 성능 요인
- CPU utilizationn : 가능한 CPU를 최대로 사용
- Throughput : 시간당 사용 가능한 프로세스 수
- Trunaround time : 프로세스가 실제 실행될때까지의 시간
- waiting time : 프로세스가 ready queue에서 대기하는 시간
- response time : request 요청에서 실제 응답까지의 시간
- FCFS(first come, first served)
- 프로세스가 진입하는 순서대로 처리
- process : burst time 가정
- P1 : 24 / P2 : 3 / P3 : 3
- 간트 차트 : 프로세스의 시작 / 종료 시간을 표현
- ex. P1, P2, P3 순 진입

- P1의 대기시간 = 0 (즉시 시작)
- 평균 대기 시간 = (0+24+27) / 3 = 17
- P2, P3, P1 순 진입

- P1의 대기 시간 = 6
- 평균 대기 시간 = (0+3+6)/3 = 3
- ex. P1, P2, P3 순 진입
- FCFS의 단점 : convoy effect
- burst time이 긴 프로세스 진입 시 다른 작업도 크게 지연
- SJF(Shortest Job First)
- burst time이 짧은 작업 먼저 : wating time이 가장 짧음
- burst time을 알아야 하는 문제 존재
- 시스템의 burst time 예측 방법 : 이전 process 실행 기록을 통한 예측
- : 실제 burst time
- : 이전에 예측했던 burst time
- (보통 0.5)
- 시스템의 burst time 예측 방법 : 이전 process 실행 기록을 통한 예측
- SRTF : SJF의 preemptive version
- 먼저 동작한 프로세스가 동작 중
- 새로운 프로세스 동작 시 남은 시간보다 새 프로세스 시간이 짧은 경우 이전 프로세스를 중단하고 새 프로세스 처리
- Round Robin
- 각 프로세스에 time quantum (q) 부여
- 모든 프로세스의 대기 시간은 (n-1)q 이하
- timer interrupt : 일정 시간이 지나면 다음 프로세스를 위해 발생
- q가 매우 커짐 - FIFO / q가 매우 작아짐 - 프로세스 전환을 위한 overhead 과다
- SJF 대비 turnaround는 크지만, response는 좋은 편
- Priority Scheduling
- 우선순위 순으로 처리
- 우선순위가 낮은 프로세스가 실행되지 않을 수 있음(Starvetion)
- 해결책 : Aging - 시간에 따라 프로세스 우선순위를 높임
- Multilevel Queue
- 우선순위가 다른 프로세스들의 배치
- 우선순위에 따라 real-time, system, interactive, batch process queue로 나누어 할당
- multilevel feedback queue
- 프로세스가 처리에 따라 다른 큐로 옮겨질 수 있음
- ex. 높은 우선순위 큐에서 다 처리되지 못한 경우, 한 단계 낮은 큐로 이동하여 처리
Thread Scheduling
- 스레드는 user-level, kernel-level로 나뉘어짐
- Many-to-one, Many-to-many의 경우 스레드 라이브러리가 동작시킬 유저 스레드를 관리
- PCS(Process-Contention Scope) : 유저 스레드 간의 스케줄링
- SCS(System-Contention Scope) : 커널 스레드간의 스케줄링
- Pthread : 스레드 라이브러리, PCS/SCS 스레드 생성을 관리
- 리눅스, MACOS의 경우 SCS로만 생성 가능
MultiProcessor Scheduling
- Symmetric Multiprocessing(SMP)
- common ready queue : global한 ready queue의 프로세스 하나를 각 코어에 나누어 할당
- per-core run queues : 각 코어가 별개의 프로세스 할당
- 최근에는 한 프로세스에 여러 코어가 할당(멀티코어 프로세스)
- 멀티스레드 / 하이퍼스레딩
- 각 코어에 1개 이상의 HW 스레드 할당
- 한 스레드는 연산(compute)와 메모리 접근(memory stall)을 번갈아 처리
- 멀티스레딩을 이용, 한 스레드가 memory stall할 때 다른 스레드로 전환하여 compute
- 멀티스레딩의 고려점
- SW상의 스레드는 OS를 통해 HW 스레드로 할당
- 코어는 각 HW스레드를 나누어 처리
- 멀티스레드 / 하이퍼스레딩
- Load Balancing
- SMP의 경우 모든 CPU가 효율적으로 작업 분배를 할 필요 존재
- Push migration : 각 프로세스 작업을 확인해 특정 프로세스에 작업이 몰릴 경우 다른 프로세스로 분배
- Pull migration : 작업이 없는 프로세스가 다른 프로세스 작업을 가져와서 처리(work stealing)
- Processor Affinity
- 어떤 프로세서에 할당하냐에 따라 작업 속도가 달라질 수 있음
- soft affinity : OS가 특정 스레드가 특정 프로세스에 작업할 수 있게 제안 (반드시 동작하지는 않음)
- Hard affinity : OS가 특정 프로세스에 affinity가 있는 스레드를 할당시킴
- ex. CPU cache : CPU 캐시의 접근속도가 메모리 대비 매우 빠르기 때문에, 직전에 작업했던 프로세스에 계속 할당시켜 주는 것이 다른 프로세스에 할당하는 것보다 더 빠름
- ex2. NUMA architecture : multi CPU - memory가 물리적으로 분리된 환경 - 간접적 연결보다 직접적으로 연결된 CPU-memory의 처리가 훨씬 빠르게 나타남
Real-Time CPU scheduling
- realtime schedule의 경우 적정 시간 내에 동작하지 못할 경우 실패로 처리
- soft real-time : 작업이 매우 높은 우선 순위를 갖고 실행
- hard real-time : 작업은 반드시 적정 시간 내에 실행
- Event latency : event가 발생 후 작업에 들어가기까지의 시간
- Interrupt Latency : 인터럽트 종류 파악 - Context Switch - ISR 접근까지의 시간
- Dispatch Latendcy : 프로세스가 가능한 상태가 된 후(인터럽트 직후) 프로세스 실행까지의 시간
- Priority-based scheduling
- 프로세스가 주기적 시간 p마다 들어온다고 가정
- 프로세스 실행까지의 제한 시간(deadline) d를 가정
- 프로세스의 처리 시간을 t로 가정
- 여야 함
- Rate Monotonic Scheduling

- rate p가 짧을수록 빠른 처리
- 우선순위가 낮은 작업 중 높은 작업 진입 시 일시 정지 후 처리
- 프로세스 작업 중 같은 프로세스가 재진입 시 deadline miss로 실행 실패

- 실행 중이던 프로세스는 처리 시간을 모두 마치지 못해 실패
- 새로 들어오는 프로세스는 설계에 따라 다름
- 먼저 실행중인 프로세스가 우선한 경우 이전 프로세스에 의해 실행 deadline을 마치지 못해 실패
- 새 프로세스가 우선하는 경우 계속 동작 (이전 프로세스만 실패)
- EDF(Earliest Deadline First)
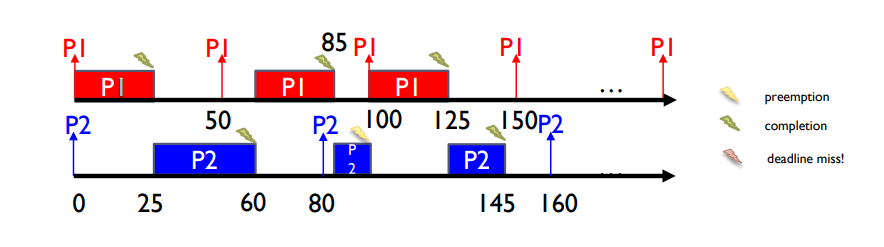
- deadline이 짧은 프로세스를 우선
OS scheduling
- Linux
- 선점형, 우선순위 기반
- 우선순위 기준 : 시분할, real-time은 별도로
- 우선순위 변수 : nice (100 ~ 140) - nice to process, 낮을수록 우선
- CPU별로 run queue를 할당
- Windows
- 우선순위 기반의 선점형
- real-time class를 별도 할당
- 0번 우선순위 : 메모리 관리
Algorithm Evaluation
- little's law
- 평균 큐 길이 n, 평균 대기 시간 W, 평균 arrival rate 일 때,
- Simulation
- 제한된 queue model
- 각 모델을 직접 동작시키면서 성능 통계를 계산
728x90